Comments
This is relatively early review thesis before pre-trained models, PTMs, went viral in late 2022 and 2023. Therefore, this thesis did not cover some recent progress in this field, including those in base models and fine-tuning techniques.
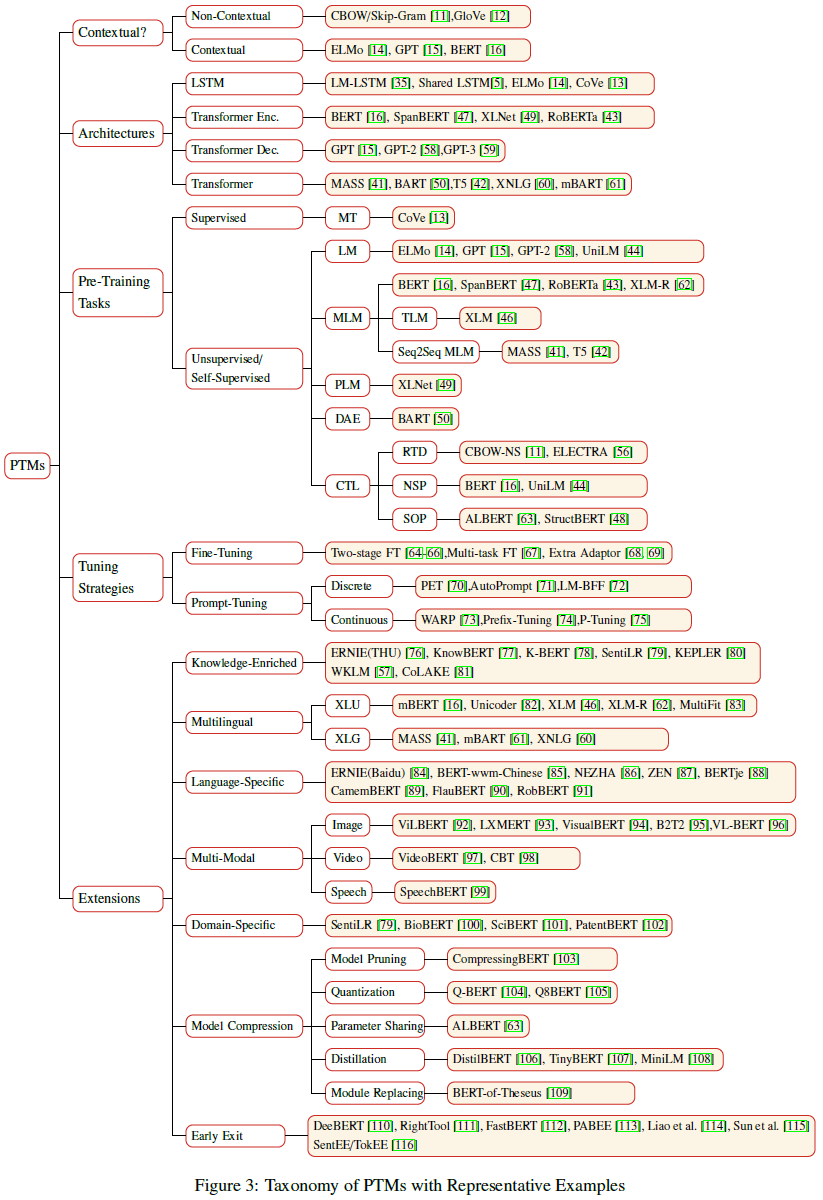
But this thesis set up a comprehensive taxonomy of PTMs and related topics, from foundation model evolutions to model architecture, pre-training tasks, tuning strategies, downstream tasks, benchmarks and model compression. It also included experimental steps and opensource resources as references for readers, which could be utilized as a thorough guidance for anyone who is new to this field.
1. Evolution History of PTMs for NLP
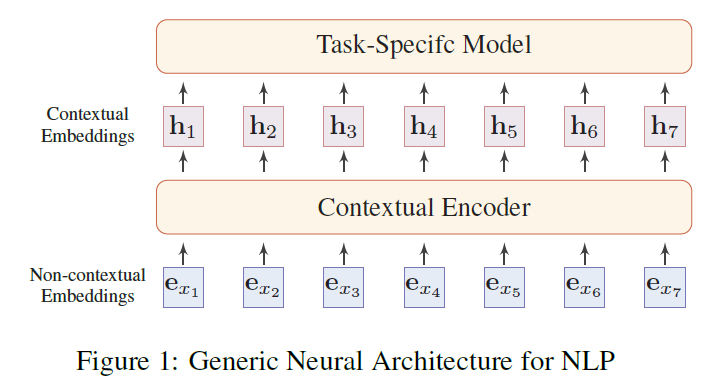
With the development of neural network algorithms in all AI field, good mathematic representation is required for text to be well calculated in learning machines or networks.
The first generation of PTMs for NLP came with this idea, vectorizing text through embedding process. The second generation, which later became the paradigm in this field, further added contextual encoder to add contextual information on original embeddings.

Among the contextual encoder methods, fully-connected self-attention models let the models learn the structure by itself. Usually, the connection weights are dynamically computed by the self-attention mechanism, which implicitly indicates the connection between words.
The self-attention mechanism is the core in Transformer architecture. From standard Transformer, now the researchers developed full-Transformer, encoder-only and decoder-only architectures to better match different downstream tasks.
2. Pretraining Breakdowns
2.1 Why Pre-training?
Unlike CV, building large-scale labeled datasets is a great challenge for most NLP tasks (except for translation tasks) due to the extremely expensive annotation costs, especially for syntax and semantically related tasks.
In contrast, large-scale unlabeled corpora are relatively easy to construct. To leverage the huge unlabeled text data, we can first learn a good representation from them and then use these representations for other tasks.
The process is called "pre-training", which is somewhat misleading since it is actually the core training process of the models. We could summarize the benefits of pretraining into several points:
Generalization capabilities gained from training on large corpus.
Pre-training provides a better model initialization, which speeds up convergence on the target task.
Pre-training can be regarded as a kind of regularization to avoid overfitting on small data.
2.2 Pretraining Tasks
Supervised learning (SL) is to learn a function that maps an input to an output based on training data consisting of input-output pairs.
Unsupervised learning (UL) is to find some intrinsic knowledge from unlabeled data, such as clusters, densities, latent representations.
Self-Supervised learning (SSL) is a blend of supervised learning and unsupervised learning. The learning paradigm of SSL is entirely the same as supervised learning, but the labels of training data are generated automatically. The key idea of SSL is to predict any part of the input from other parts in some form. For example, the masked language model (MLM) is a self-supervised task that attempts to predict the masked words in a sentence given the rest words.
Because large, labeled data is not commonly available in NLP field, most of current models use SSL methods to pretrain.
Language Modeling (LM): in practice, LM often refers in particular to auto-regressive LM or unidirectional LM.
Masked Language Modeling (MLM): MLM first masks out some tokens from the input sentences and then trains the model to predict the masked tokens by the rest of the tokens.
Permuted Language Modeling (PLM): In short, PLM is a language modeling task on a random permutation of input sequences. The model is trained to fill the random blanks (masked tokens) in a randomly permuted sequence. In practice, only the last few tokens in the permuted sequences are predicted to accelerate convergence.
Denoising Autoencoder (DAE): Denoising autoencoder (DAE) takes a partially corrupted input and aims to recover the original undistorted input. Masking is one of the techniques used as noise. The core idea behind this is to make models learn semantic and sequential patterns by training them in reconstruction tasks.
Contrastive Learning (CTL): Contrastive learning assumes some observed pairs of text that are more semantically similar than randomly sampled text. Because it only compares the differences, it requires less computational power.
3. Enhancing Foundation PTMs
3.1 Knowledge-Enriched PTMs
Incorporating domain knowledge from external knowledge bases into PTM has been shown to be e ective. The external knowledge ranges from linguistic, semantic, commonsense, factual, to domain-specific knowledge.
3.2 Multi-Modal PTMs
3.3 Model Compression
Model Pruning refers to removing part of neural network (e.g., weights, neurons, layers, channels, attention heads), thereby achieving the effects of reducing the model size and speeding up inference time.
Quantization refers to the compression of higher precision parameters to lower precision. It often requires compatible hardware.
Parameter Sharing also reduces the number of parameters. It does not improve the computational efficiency at inference phase.
Knowledge distillation (KD) is a compression technique in which a small model called student model is trained to re produce the behaviors of a large model called teacher model.
4. Adapting PTMs to Downstream Tasks
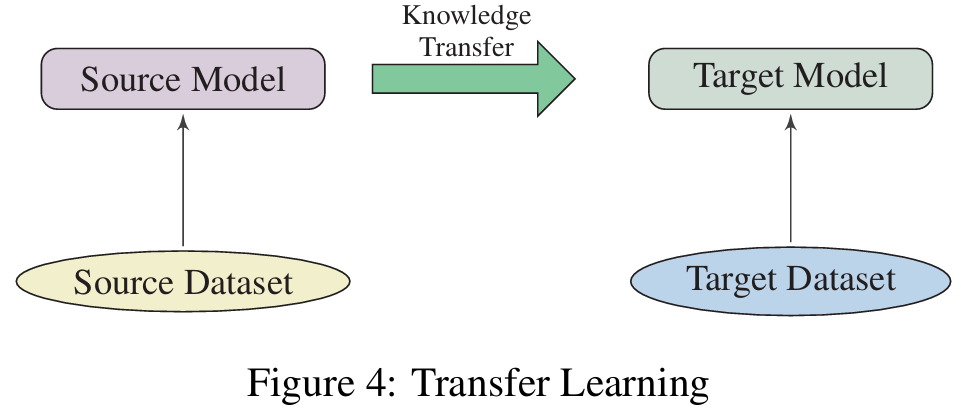
4.1 Transfer Learning & Fine-Tuning
Transfer learning is to adapt the knowledge from a source task (or domain) to a target task (or domain).
Before transferring, we need to determine on 3 factors:
What: building right base model for the right downstream tasks by choosing proper pre-training tasks, model architecture and corpus.
Where & How: choosing proper layer of the base model and decide whether feature extraction or fine-tuning techniques will be conducted.
By the time this thesis was published, fine-tuning was still relatively new area. But recent advancements could still be categorized into the 2 types mentioned in this chapter:
Parameter efficient fine-tuning, including later LoRA and different adaptors that focus on updating some of the parameters in the original model.
Prompt-based fine-tuning methods, which focus more on using existed trained mechanism from the model and fine-tune it by adjusting prompts.
4.2 Downstream Tasks/Applications
General Evaluation Benchmark:
The General Language Understanding Evaluation (GLUE) benchmark is a collection of nine natural language understanding tasks, including single-sentence classification tasks (CoLAandSST-2), pairwise text classification tasks (MNLI, RTE, WNLI, QQP, and MRPC), text similarity task (STS B), and relevant ranking task (QNLI).
Compared to GLUE, SuperGLUE has more challenging tasks and more diverse task formats (e.g., coreference resolution and question answering).
Other common tasks/applications:
Question Answering
Sentiment Analysis
Named Entity Recognition
Machine Translation
Summarization
Adversarial Attacks and Defenses
5. Future Directions & Conclusion
The authors listed 5 future directions at the end. 5 years gone from its published date, first 4 of them have been advanced tremendously:
Upper Bound of PTMs
Architecture of PTMs
Task-oriented Pre-training and Model Compression
Knowledge Transfer Beyond Fine-tuning
Interpretability and Reliability of PTMs
The last one remains unresolved partially due to business competition and geopolitical reasons.