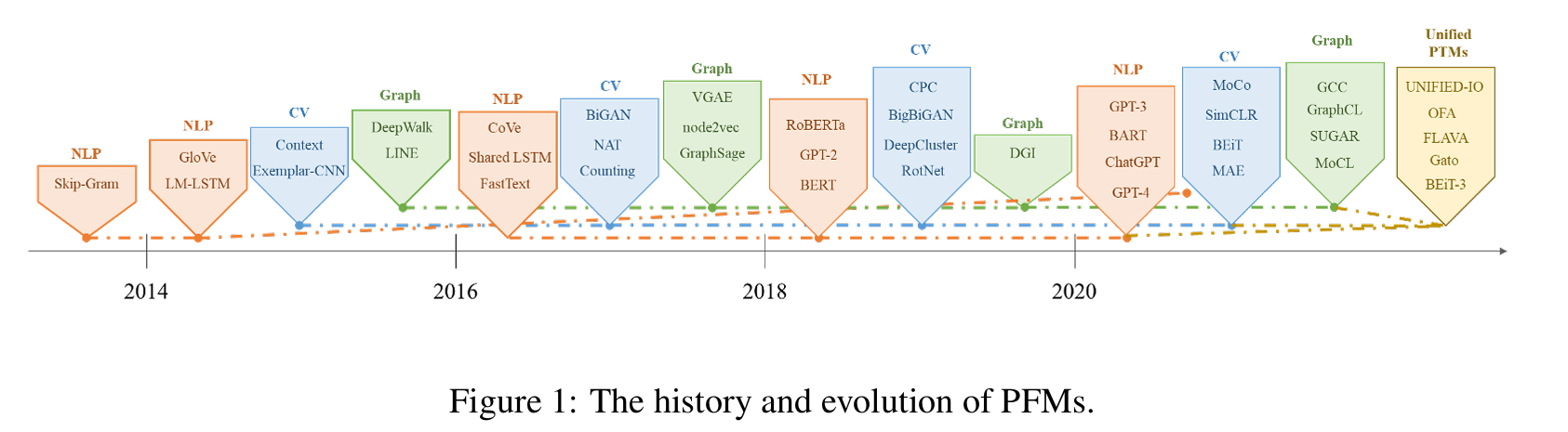
 The original paper is available on arXiv: [2302.09419] A Comprehensive Survey on Pretrained Foundation Models: A History from BERT to ChatGPT
The original paper is available on arXiv: [2302.09419] A Comprehensive Survey on Pretrained Foundation Models: A History from BERT to ChatGPT
1. Introduction & Overview
This is an article published in May, 2023, when GPT-4 was only launched for 2 months.
As a survey, this article covers most of the main aspects of pre-trained foundation models, PFMs, at that time.
It introduced a taxonomy to classify PFMs based on their targeted tasks: Natural Language Processing, Computer Vision, Graph Learning and multimodal.
It mentioned some advanced topics in this field but did not elaborate on them, including model efficiency, model compression, security and privacy issues.
Challenges and open problems are stated but nothing special for someone in this field from 2025.
It provided a thorough and comprehensive appendix which dives deeper on the theoretical introductions of the PFMs and their methods. It also provides a concise list of downstream tasks in this field with corresponsive datasets.
Overall, this is very accomplished survey for anyone who just started in this field. I found it particularly helpful since it provided a complete guidance for anyone who wants to get their hands-on a mainstream task, with a tested dataset.
2. Discussion Scope in this Literature
The taxonomy used in this article is mainly focused on the datatype of input. Hence, this survey did not include recent popular generative models like diffusion-based picture or video generation models or transformer-based world simulation models.
Except for theoretical elaborations in the appendix, this article mainly used the findings from its citations to organize the contents. This article does not provide any empirical validation for the cited materials. I believe this is part of the reason why the authors could not bring up innovative ideas in the conclusion chapter.
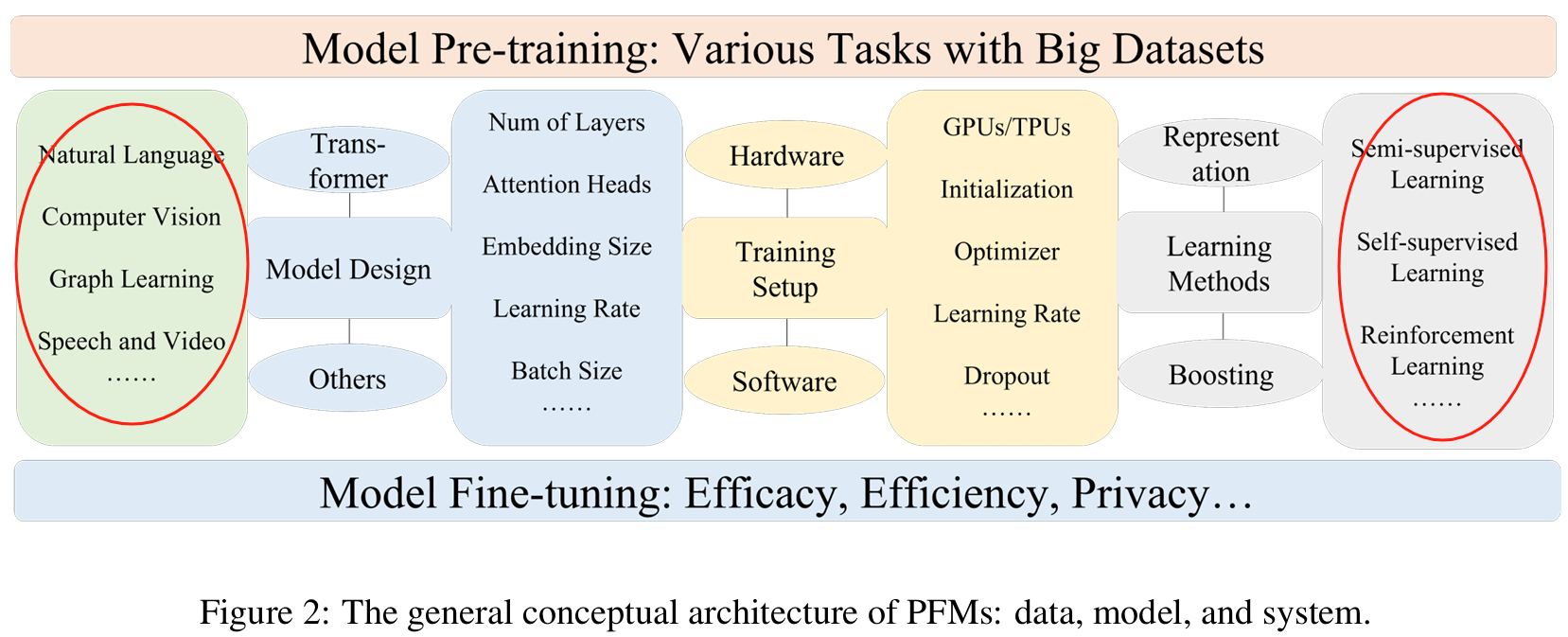
As I mentioned, this survey classified PFMs by their input datatypes and the main chapters are as followed, and you may also notice that the subsections are organized by the learning methods of the models to delivery best performance on different tasks:

3. Basic Components
This chapter serves as a pre-context for the following chapters.
It answers 3 main questions in 3 sub-sections, respectively:
What is the model architecture? —— Transformer is the mainstream one.
What learning mechanisms are there to select? How do you know when to select which? —— Supervised/ Semi-supervised/ Weakly-supervised/ Self-supervised
What tasks we use to pretrain the models? —— For NLP, CV and GL.
Information covered in this chapter will later be utilized as "components" in detailed descriptions on how PFMs are designed, constructed and boosted with these "components" to process different input data.
4. PFMs for NLP
There are 2 main directions of LM for NLP
Autoregressive LM: GPT is the most famous representative. It could predict the following words based on contextual information from former text, which makes it perfect fit for generation tasks.
Contextual LM: BERT is the most famous one. The bi-directional model could use information above and below at the same time. This makes it better perform on text summary and sematic understanding tasks when compared to autoregressive LMs.
Permuted LM: Combined the 2 types of methods from autoregressive and contextual to get balanced performance on all types of tasks
Design, Training and Boosting PFMs
Still BERT vs GPT, and BART, which introduces noises to help model build comprehensive capabilities.
Additionally, since masking is the core mechanism in training LMs, this chapter brought up different masking techniques used in BERT and GPT, with a more advanced joint training model MASS, which could conduct training in both encoder and decoder at the same time.
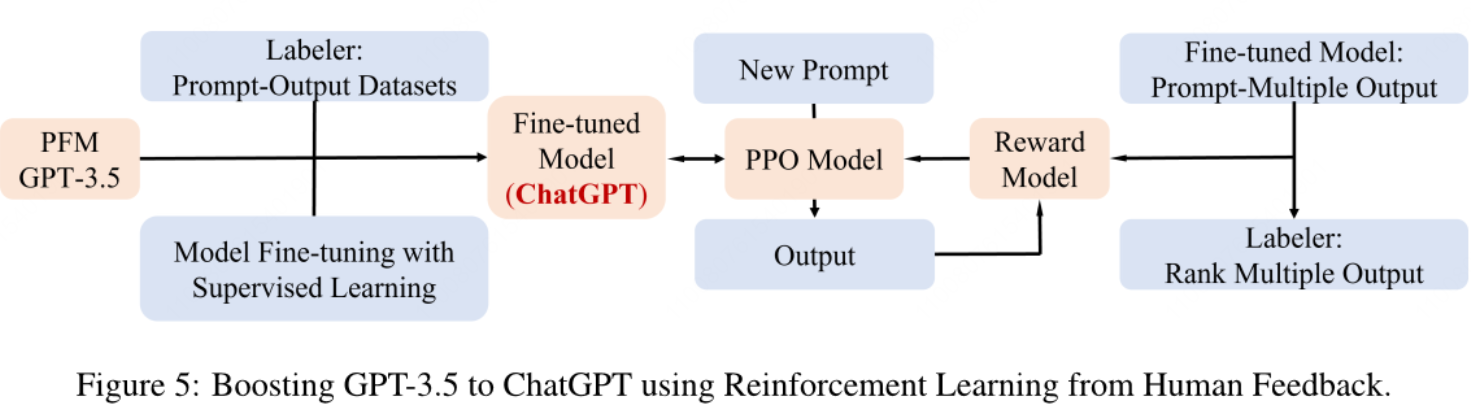
To boost model performance, there are several different methods:
Compressing the model to make retrain or fine-tuning easier
Differentiating pretraining methods by downstream tasks and use reward models to further enhance the task-oriented performance
Instruction-Aligning methods like supervised fine-tuning, reinforcement learning and chain-of-thoughts to make outputs better align with human expectation.
5. PFMs for Computer Vision

This chapter focusing on introducing different pretraining methods utilized in CV area.
5.1 Learning by Specific Pretext Task
The figure above shows what "specific pretext tasks" could be like.
5.2 Learning by Frame Order
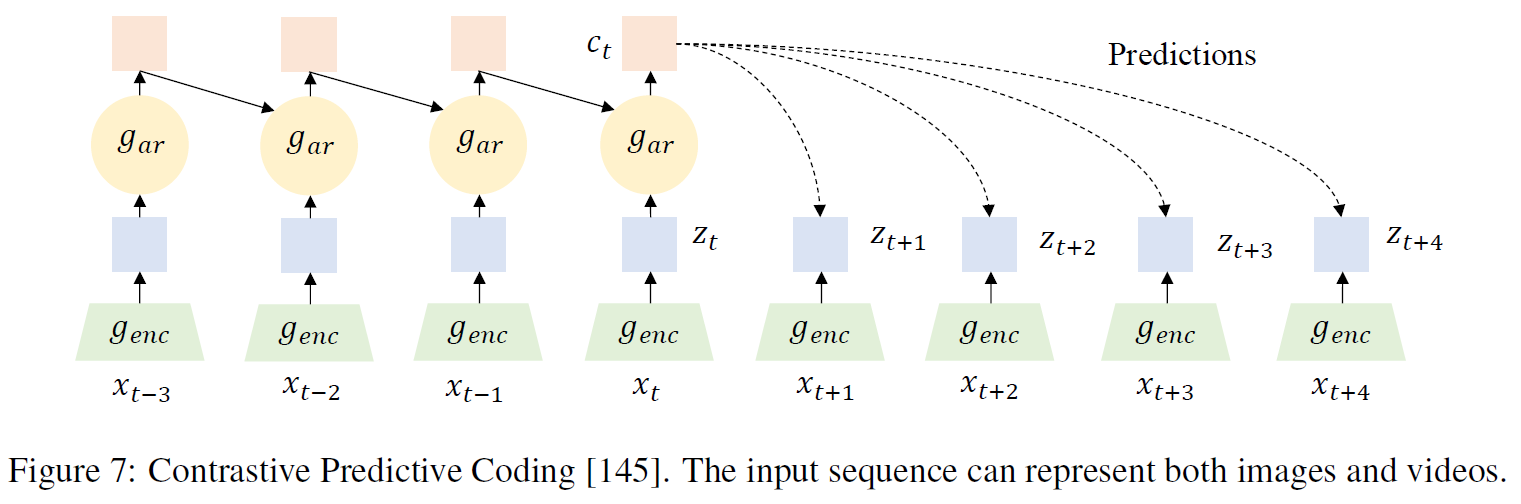
Contrastive Predictive Coding, CPC, is the most commonly used model to predict frames with time sequence order.
5.3 Learning by Generation
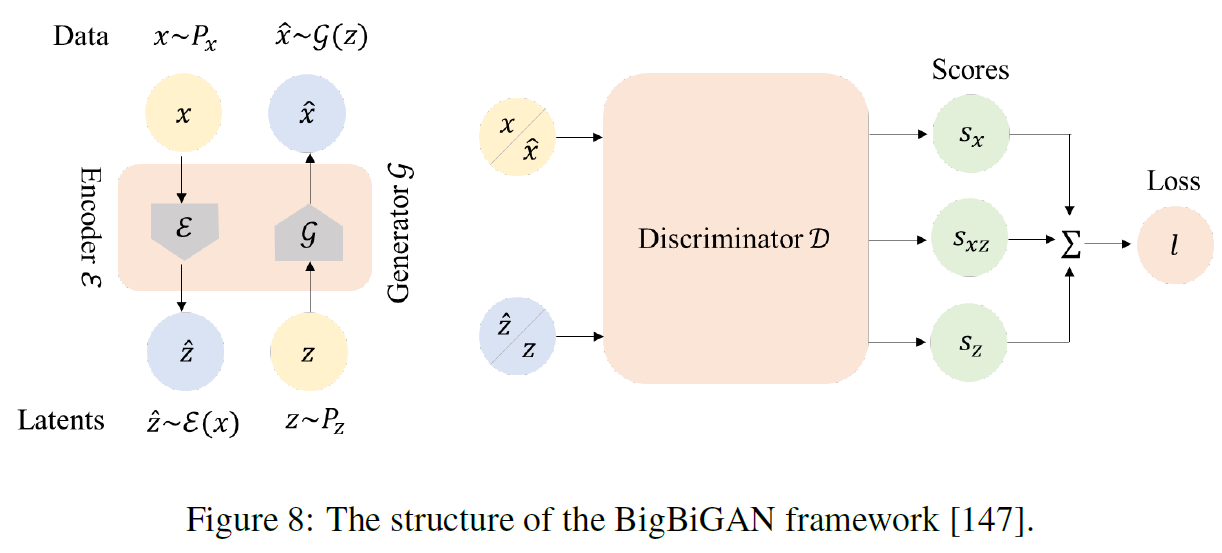
BiGAN introduces a feature encoder into GAN-based models to help generate better image, which eventually accelerates the converging.
5.4 Learning by Reconstruction
Note that this is the mainstream method in this area since Transformer became popular in 2022. Famous model like MAE from facebook demonstrates how the experience from Transformer in NLP could be utilized in CV.
Basically, reconstruction methods require people to first divide image into patches, then use random masked combination of patches to predict and reconstruct what is masked.
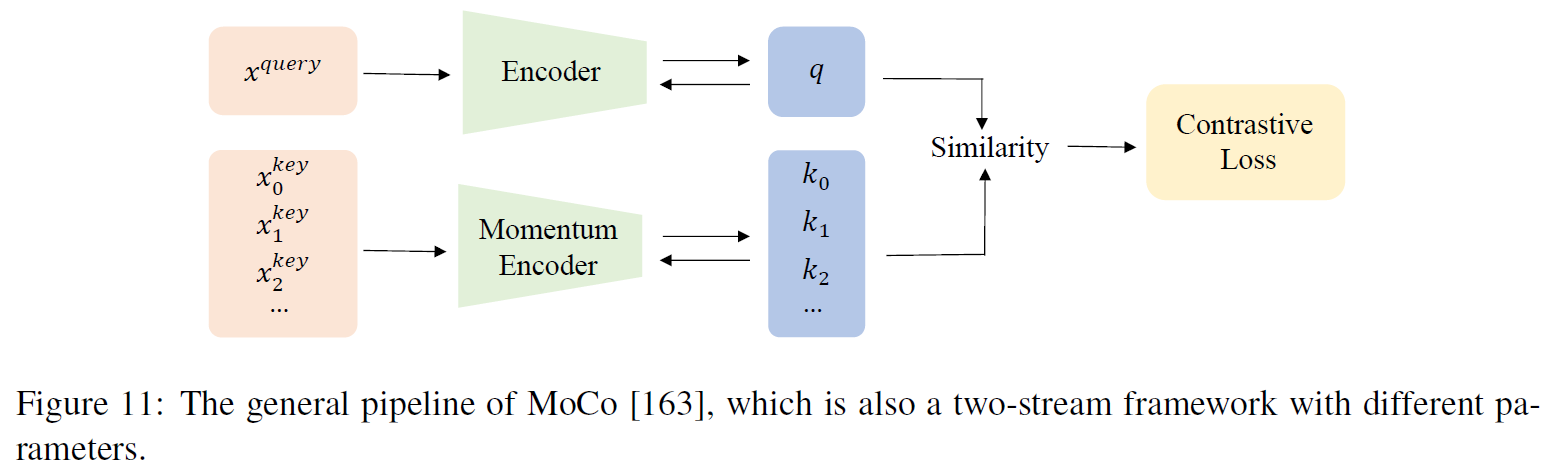
5.5 Learning by Memory Bank
Pre-defining all image representations and store them in memory bank for comparison with inputs as negative sample.
5.6 Learning by Sharing
SSL prefers using two encoder networks for the different data augmentation, and then pretrains the parameters by maximizing the distance between negative pairs or minimizing the distance between positive pairs.
Soft sharing: 2 encoders have similar but not identical parameters.
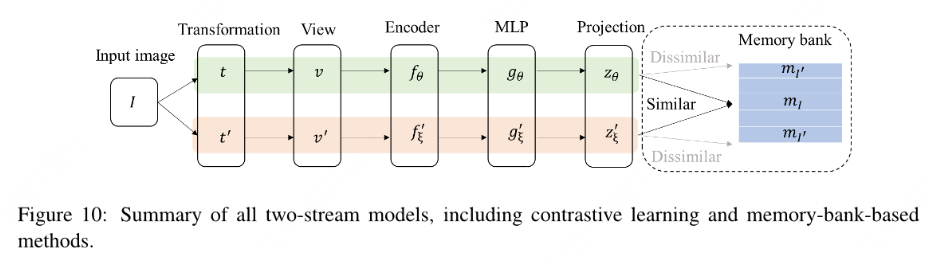
Hard sharing: 2 encoders have identical parameters.
5.7 Learning by Clustering
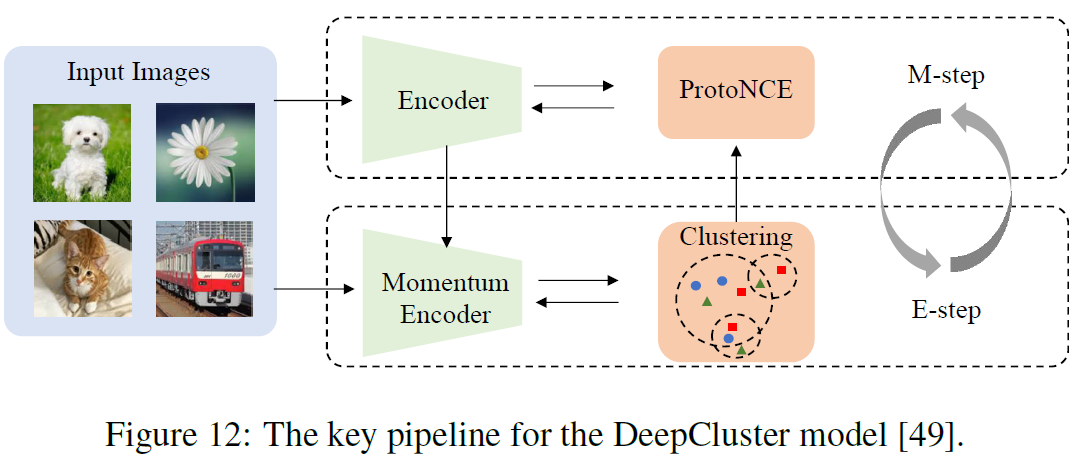
This method groups the representations into different clusters and labels these clusters as supervised signals to pretrain the parameters of the backbone network. It's also a soft-sharing method.
Chapter Summary
Because GAN is the mainstream method in image generation, many recent research use a combined method of GAN + Transformer to better utilize large pretrain datasets and improve the generalization capabilities of base models.
6. PFMs for GL
Graph data have the attributes similar to text and image at the same time. Therefore, graph learning PFMs also combined the methods used in NLP and CV areas, including different masking techniques, contrastive learning and clustering learning.
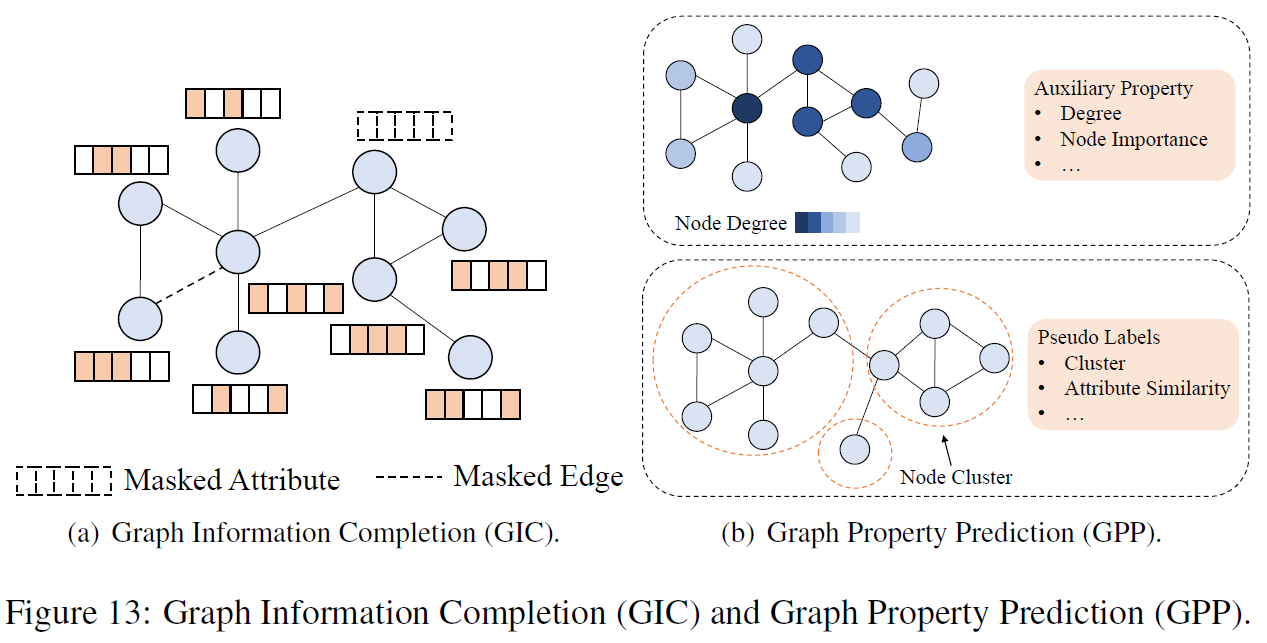
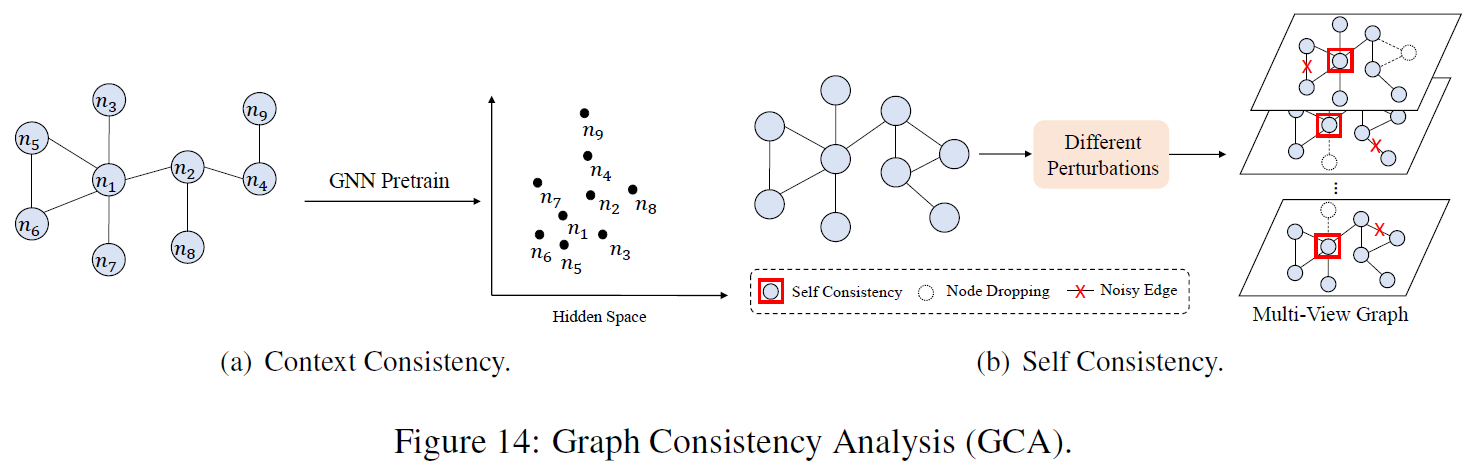
Self-supervised learning is also a paradigm in graph learning since labeled graph data is not as commonly available as text or image data.
MGAE-based methods, which combine Transformer and reconstructive learning, are the mainstream recently.
7. PFMs for Other Data Modality
PFMs for Speech
Discretizing the original continuous speech signal, so that the methods in the mature NLP community can be migrated and applied.
PFMs for Video
Video is similar to the RGB features of image and sequence information of the text.
Multi-modal PFMs
Including 2 categories, single-stream and cross-stream models. Cross-stream models first encode different type of data in separate encoders and then combine the information together through a transformer architecture. I believe this method is by far better than single-stream method since different modality has its own best practice on pretraining.
8. Other Advanced Topics and Future Outlooks
The last 2 chapters discussed some advanced topics in this field, including model efficiency, model compression, security and privacy. Nothing special in this part though.
As an article published in mid-2023, some of the challenges have been overcame by later research but there are still some open questions unanswered. The main one I noticed is lack of attention on graph knowledge, especially for multi-modal PFMs. This issue is not resolved properly may be because graph data is not as generally available as data in other modalities.